wtorek,
Compute Unified Device Architecture
8 listopada 2006 roku firma nVidia przedstawiła technologię CUDA.
Compute Unified Device Architecture to technologia umożliwiająca wykorzystanie mocy obliczeniowej procesorów kart graficznych do rozwiązywania ogólnych problemów numerycznych wykorzystująca uniwersalną architekturę procesorów wielordzeniowych umożliwiającą działanie tysięcy wątków na każdym z rdzeni w sposób wydajniejszy niż w tradycyjnych procesorach. Efektem wykorzystania CUDA może być znaczne przyśpieszenie pracy programów komputerowych. Obecnie możliwości te są szeroko wykorzystywane m.in. w oprogramowaniu wykonującym obliczenia rozproszone, konwerterach audio i wideo oraz grach komputerowych.
Dla programistów opracowano odpowiednie środowisko oparte na języku programowania C. Dostępne są m.in. specjalny kompilator (nvcc), debugger (cuda-gdb), profiler oraz interfejs programowania aplikacji. Dzięki dodatkowym bibliotekom z możliwości CUDA można korzystać z poziomu takich języków, jak Python, Fortran, Java, C#, Perl, Ruby oraz Matlab. 15 lutego 2007 roku opublikowano zestaw narzędzi dla programistów CUDA software development kit. CUDA SDK początkowo wspierał systemy Microsoft Windows i Linux, w jego drugiej wersji dodano obsługę Mac OS X.
Przykładowy program
Procedurę instalacji pakietu CUDA Toolkit dla systemów Windows, Mac OS i Linux znajdziesz w dokumentacji udostępnionej przez producenta. Poniżej zaprezentowano komendę umożliwiającą instalację wymaganych narzędzi w systemie Ubuntu.
sudo apt install nvidia-cuda-toolkitPrzykładowy program to hello-ckziu, wariacja na temat „Hello World!”. Aby zademonstrować niektóre funkcje korzystające z CUDA, proste zadanie wypisania zadanego tekstu zostało zrealizowane w dość rozwlekły sposób.
#include <stdio.h>
const int N = 16;
const int blocksize = 16;
__global__
void hello(char *a, int *b)
{
a[threadIdx.x] += b[threadIdx.x];
}
int main()
{
char a[N] = "Hello \0\0\0\0\0\0";
int b[N] = {-5, -26, -18, -3, -26, 1, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0};
char *ad;
int *bd;
const int csize = N*sizeof(char);
const int isize = N*sizeof(int);
printf("%s", a);
cudaMalloc( (void**)&ad, csize );
cudaMalloc( (void**)&bd, isize );
cudaMemcpy( ad, a, csize, cudaMemcpyHostToDevice );
cudaMemcpy( bd, b, isize, cudaMemcpyHostToDevice );
dim3 dimBlock( blocksize, 1 );
dim3 dimGrid( 1, 1 );
hello<<<dimGrid, dimBlock>>>(ad, bd);
cudaMemcpy( a, ad, csize, cudaMemcpyDeviceToHost );
cudaFree( ad );
cudaFree( bd );
printf("%s\n", a);
return 0;
}
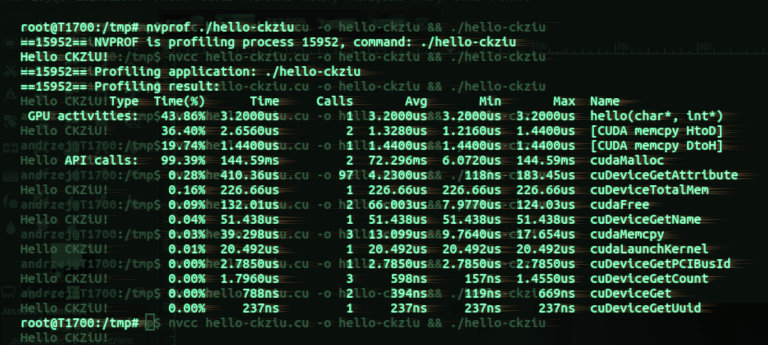
Kompilacja i wykonanie programu w środowisku Linux. Źródła zapisano jako hello-ckziu.cu.
nvcc hello-ckziu.cu -o hello-ckziu && ./hello-ckziuProfilowanie programu hello-ckziu.cu.